Phrase Retrieval and Beyond
Oct 5, 2021 | Written by Jinhyuk Lee
When I started my internship at NAVER in November 2018, I got an opportunity to participate in a research project led by Minjoon Seo.
At that time, Minjoon and his colleagues were proposing the concept of “Phrase-Indexed Question Answering” [1], which formulates extractive question answering as retrieving pre-indexed phrases (hence later extended to phrase retrieval) and brings a significant scalability advantage over existing QA models.
Ever since I started working on this project, I’ve spent a lot of time developing better phrase retrieval models [2, 3, 4], but didn’t have a chance to talk about the story behind the scene and the connection of recent work we did in this line of research.
In this post, I’m going to introduce what phrase retrieval is and what progress has been made, convincing you that this is an important/interesting topic.
Each section will cover a paper and explain its contributions. All the references are listed at the end.
- Background: Cross Attention for Extractive QA
- Phrase-Indexed Question Answering [1]
- Phrase Retrieval for Open-Domain QA [2]
- Learning Sparse Phrase Representations [3]
- Dense Phrase Retrieval and Beyond [4]
- Phrase Retrieval Learns Passage Retrieval, Too [5]
- Conclusion
Background: Cross Attention for Extractive QA
In reading comprehension, a model is given a passage and a question posed by humans and the model has to find an answer from the passage. Many NLP models and datasets often assume that the answers exist as an exact span in the given passage (or as a phrase extracted from the passage), and this is called extractive question answering (QA). Cross attention is one of the most widely used techniques in many extractive QA models, which allows rich interaction between passage and question words. One example would be feeding concatenated passage and question words into a model with a self-attention mechanism like BERT [6]. Then the model is trained to output a probability distribution over the passage words whether they are start (or end) of the answer.
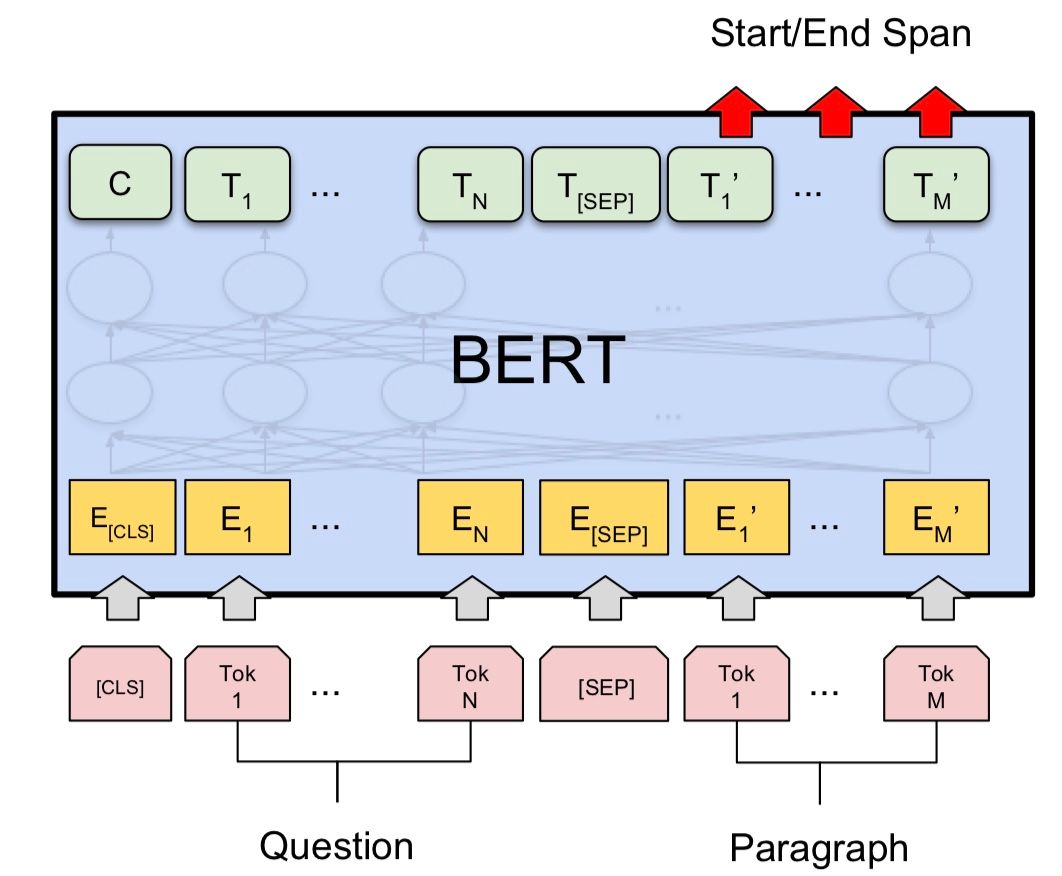
Figure 1. An example of using cross attention for reading comprehension using BERT. Image credit: Devlin et al., 2019.
But, imagine that we are not given a particular passage but want to read every single Wikipedia passage to find an answer for a question (this is basically what open-domain question answering aims to do). Cross-attention models would scale terribly since we have to compute the attention score of every combination of input words at every layer. For instance, if we are only given a single CPU, BERT-large will process 51 words per second, and it will take about 681 days (!) to process 21 million passages (assuming the attention is computed per passage) in Wikipedia. Phrase retrieval is proposed to mitigate this problem and enables reading the entire Wikipedia within a second. Before introducing what phrase retrieval is, we first need to understand what phrase-indexed question answering is.
Phrase-Indexed Question Answering
In EMNLP 2018, Seo et al. [1] presented the idea of “Phrase-Indexed Question Answering” (PIQA), where extractive QA is reformulated as retrieving pre-indexed phrases. Here the definition of a phrase is any contiguous text segment including a single word. PIQA works by first pre-computing and indexing all the phrase vectors from passages and finding an answer by performing maximum inner product search (MIPS), which means simply finding a phrase vector that has the maximum inner product score with a question vector.
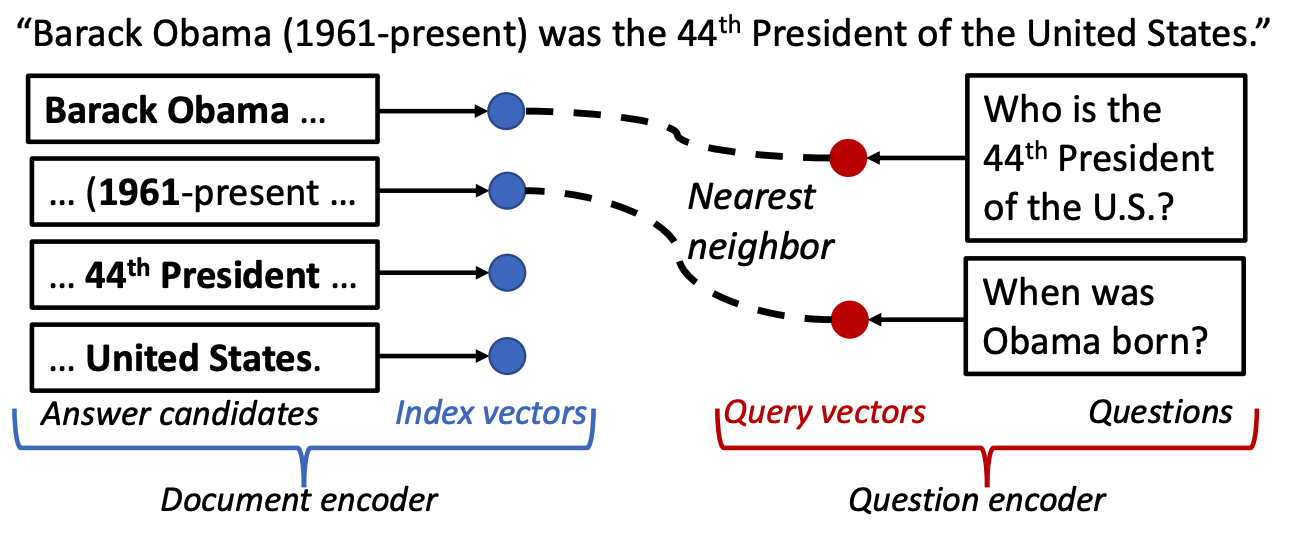
Figure 2. Phrase-indexed question answering. Image credit: Seo et al., 2018.
The way phrases are encoded from the passage is very straightforward.
First, each phrase vector is represented by the concatenation of start and end token vectors from the passage.
Among many other phrases in the passage, the model is trained to maximize the score of a gold phrase that answers the question.
Note that we also encode questions independently and use QA datasets like SQuAD to train the model.
Also, each passage token is supervised by the answer annotation in QA datasets so that we can filter out tokens that are not likely to form a valid phrase.
Later on, this filtering strategy largely reduces the size of a phrase index (a collection of phrase vectors).
Once the passages are processed by a phrase encoder (denoted as Document encoder in Figure 2) to pre-compute phrase vectors, all we need to do during the inference is 1) to compute the question vector from a question encoder and 2) find an answer with MIPS.
Now, for any incoming questions, we don’t need to re-read any passages but just re-use the pre-indexed phrase vectors to find an answer.
Since the inference time for computing the question vector is relatively trivial (compared to reading multiple long passages) and MIPS can be efficiently implemented with sub-linear time search algorithms, this type of model can be very useful when scaling extractive QA models.
While conceptually simple, Seo et al. (2018) [1] didn’t actually evaluate their model in a large-scale setting such as using the entire Wikipedia (i.e., open-domain QA), but only evaluated it on the reading comprehension setting where a single gold passage is given for each question.
In this setup, they pointed out that since we now need to process the passages in a query-agnostic way, meaning that our passage representations are not informed by the posed question as in cross attention models (compare Figure 1 and 2), the performance of PIQA falls greatly behind existing extractive QA models as shown in Table 1.
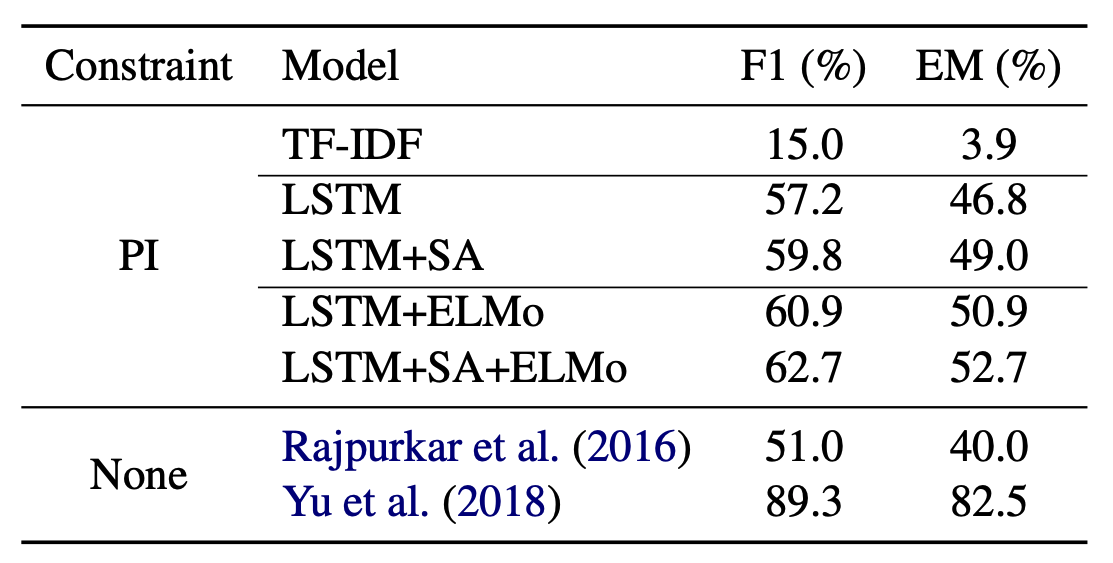
Table 1. Phrase-indexed QA models (denoted as PI) fall behind existing QA models.
Evaluated on SQuAD where a single gold passage is given for each question.
This observation can be understood as the gap between dual-encoder and cross-encoder models, which is often discussed in the literature of information retrieval. Given the philosophy of PIQA, we are now ready to talk about phrase retrieval.
Phrase Retrieval for Open-Domain QA
Remember that open-domain QA aims to find an answer to a question from the entire Wikipedia. Since the cost of reading the entire Wikipedia with a cross-attention model is too high, the retriever-reader approach (initiated by Chen et al. (2017) [7], see Figure 3) uses a first-stage document (or passage) retriever to find top k relevant documents, so that a heavy reader model only has to read a fewer number of documents. Many open-domain QA models at that time were based on this approach and it is still a dominating approach (e.g., ORQA, DPR, FiD).
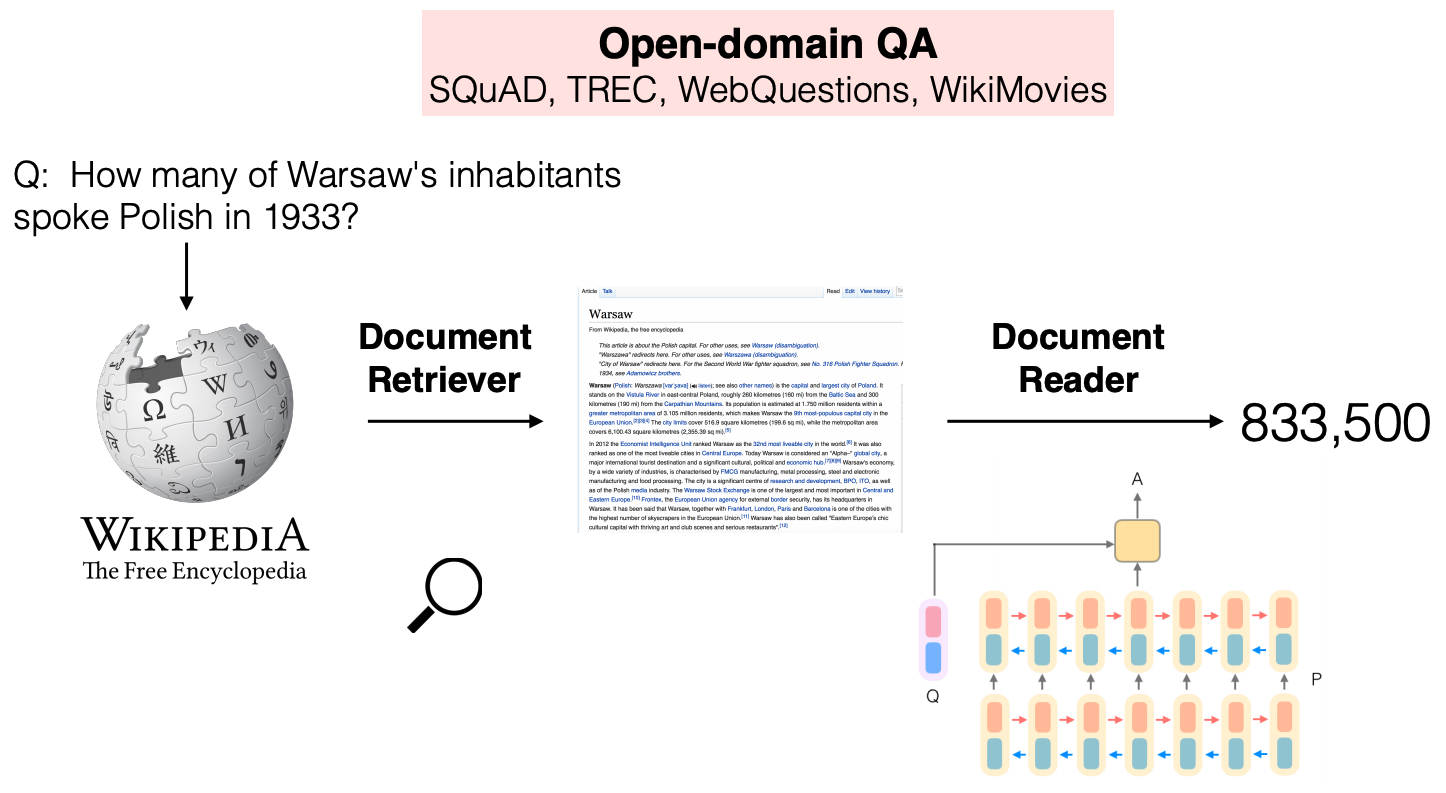
Figure 3. An example of the retriever-reader approach called DrQA [7]. DrQA retrieves top 5 documents from Wikipedia with Document Retriever and these documents are processed by Document Reader based on Bi-LSTM. Image credit: Chen et al., 2017.
Although widely adopted in many open-domain QA models, retriever-reader approaches still need to process about hundred passages for every question with heavy reader models.
For instance, a state-of-the-art reader model for open-domain QA requires 64 32GB V100 GPUs for training, which is very difficult to afford in academia [8] and is prohibitively slow to run without GPUs.
In addition to the complexity issue, the retriever-reader approach can suffer from error propagation since the reader model will never be able to find the answer if the document retriever fails to retrieve documents that contain the answers.
Based on the spirit of PIQA, we proposed phrase retrieval [2] to tackle these limitations.
Conceptually, phrase retrieval is simply an open-domain QA extension of PIQA.
Our model called DenSPI (Dense-Sparse Phrase Index) pre-encodes billions of phrase vectors from the entire Wikipedia and the answer is retrieved by performing MIPS over the phrase vectors.
As shown in Table 2, its performance is competitive to the existing open-domain QA models (in retriever-reader approaches) with a much faster inference time.
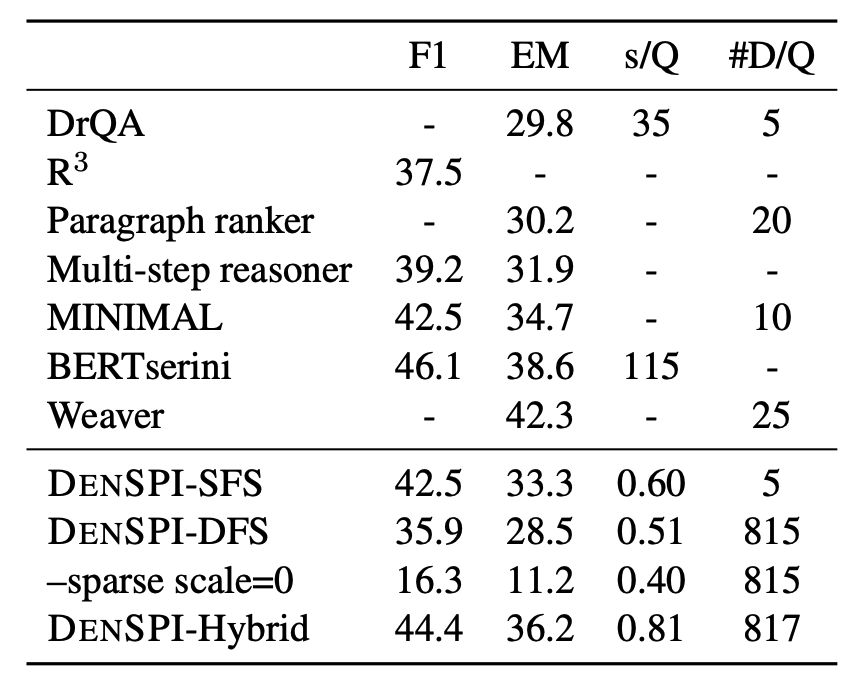
Table 2. DenSPI-Hybrid performs on par with existing open-domain QA models (F1 = 44.4) while running very fast during inference (0.81 s/Q = sec/question). Evaluated on SQuAD-open and inference time measured with a CPU.
While it looks simple, implementing phrase retrieval required contributions from both the research and engineering sides.
The main challenges were 1) how we can perform accurate retrieval over 60 billion phrases (assuming 3 billion words in Wikipedia, maximum of 20 words for each phrase) and 2) how we can store 60 billion phrase vectors efficiently (naive implementation will require 240TB to store all the phrase vectors).
In [2], we were able to achieve a decent accuracy by combining trained dense vectors and static sparse vectors such as TF-IDF (this is the reason why it is called Dense-Sparse Phrase Index). We also reduced the storage from 240TB to 1.2TB with various engineering efforts including the use of pointer, filtering, and quantization.
Another nice thing about phrase retrieval is that we no longer have to train two separate models—a retriever and a reader—for open-domain QA but only need to focus on the phrase retriever that directly outputs the answers since it doesn’t require a reader model.
Indeed, there are many recent works that study the complex interplay between the retriever and the reader (e.g., Izacard and Grave, ICLR’21, Yang and Seo, 2020), but improving the retriever doesn’t guarantee better open-domain QA accuracy since we need to train another reader model given the new passage distribution.
Since phrase retrieval is not a pipeline model, it doesn’t have such a problem and improvement in the phrase retriever will always translate to better open-domain QA accuracy.
Learning Sparse Phrase Representations
Although we were very excited about the results of DenSPI, the field of open-domain QA progresses really fast, especially based on the retriever-reader approach.
Soon after we published the results, stronger retriever-reader models came out, which made the accuracy of DenSPI look less appealing.
Also, the requirement for storing 1.2TB of phrase vectors was definitely not something everyone can afford (it even required SSDs to make disk-based vector search faster).
Our first focus to improve the accuracy of DenSPI was to develop sparse vectors that better contextualize each phrase.
Since the sparse vector used in DenSPI was static (we used document and paragraph-level TF-IDF), it gave the same sparse vector for each phrase within the same passage, hence only acting as a coarse-level feature.
What we wanted to do is to contextualize the sparse vectors and make every phrase within the passage have a different sparse vector, focusing on different entities in the passage.
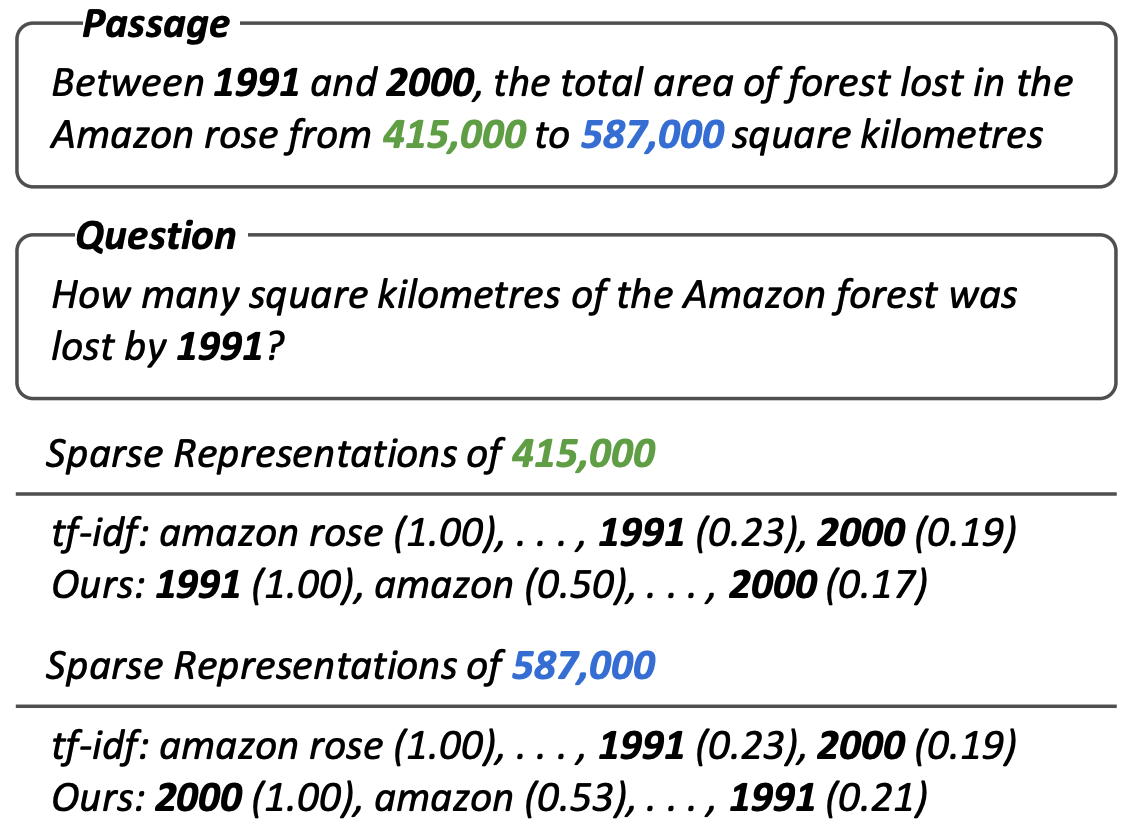
Figure 4. A motivating example of Sparc [3]. The proposed sparse vector is contextualized
so that every phrase has a different sparse vector. Image credit: Lee et al., 2020.
While this Contextualized Sparse representation (Sparc [3]) improved DenSPI by more than 4% absolute accuracy, there were clear disadvantages of this approach.
First, concatenating another representation to each phrase was obviously not scalable.
Although we managed to minimize the computational cost of using more sparse vectors, it inevitably increased the disk footprint of the phrase index (that holds the entire pre-computed phrase vectors) from 1.2TB to 1.5TB.
Second, relying on the sparse vectors has a clear limitation because they are based on lexical matches, causing lots of false positives and negatives.
Third, since it is difficult to build a MIPS index for dense + sparse vectors (no public libraries supported this feature at that time), the search process was very complicated and didn’t seem to fully enjoy the efficiency of MIPS algorithms.
So I started looking out for a learning method that can produce better dense representations of phrases, which can keep the size of the phrase index the same in theory and improve the performance by learning better semantic matching.
After spending about a year on this problem, we (together with Danqi Chen from Princeton University) developed a model called DensePhrases, which I’ll explain in the next section.
Although we decided to remove the sparse representations from our model, I still think contextualized sparse representations can be further improved and applied to many applications in NLP (e.g., numerical reasoning) due to their strong lexical precision.
Dense Phrase Retrieval and Going Beyond
The main goal of DensePhrases [4] was to get rid of sparse vectors from phrase retrieval. We didn’t like the aspect of phrase retrieval models heavily relying on the sparse vectors (due to the reasons mentioned above), but their accuracy was pretty low without sparse vectors (see Table 2 where sparse scale=0) and it was very challenging to build fully dense representations of phrases at a billion scale. Of course, more powerful open-domain QA models kept coming out! Among them, we were particularly inspired by works on learning dense representations of passages (ORQA by Lee et al., ACL’19, DPR by Karpukhin et al., EMNLP’20). However, due to the different scales and granularities, we had to start from scratch by examining architectural details and learning methods of phrase retrieval. And, following is the performance of DensePhrases with fully dense representations of phrases.
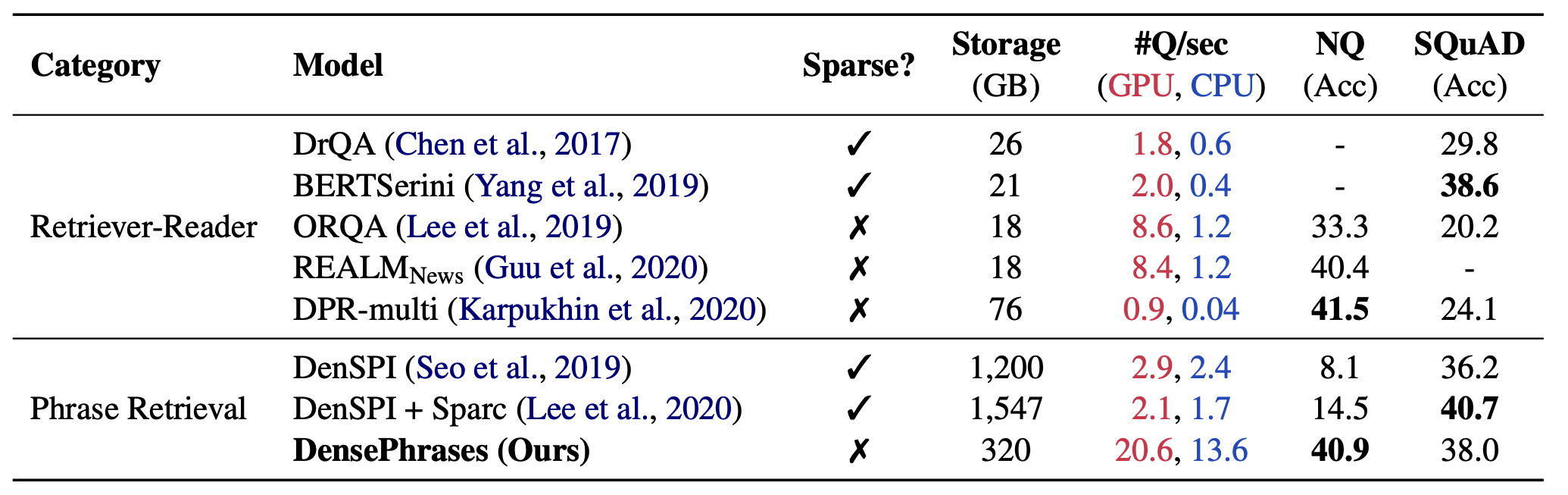
Table 3. Comparison of different open-domain QA models including DensePhrases. #Q/sec: the number of questions processed per second. NQ denotes Natural Questions (Kwiatkowski et al., TACL'19).
To learn fully dense representations of phrases, we changed everything from pre-trained LMs (e.g., using SpanBERT by Joshi et al., TACL’20) to learning methods (e.g., in-batch negatives and query-side fine-tuning). Phrase retrieval is now competitive with state-of-the-art open-domain QA models such as DPR (Karpukhin et al., EMNLP’20) but also more scalable since it requires only 320GB (huge reduction from 1.5TB). It got even faster than previous phrase retrieval models as demonstrated in Figure 5 as well.

Figure 5. DensePhrases showing real-time results (100ms/question) for open-domain questions.
For every question, it shows top k phrases (denoted in boldface) as well as their original passages.
The demo is available at http://densephrases.korea.ac.kr.
The main technical contributions of DensePhrases can be summarized as follows.
- In-batch / pre-batch negatives: motivated by the literature on contrastive learning, we applied in-batch negatives, which has also been shown to be effective for dense passage representations [9]. We also proposed a novel variant of negatives called pre-batch negatives where representations from recent mini-batches are cached and used as negative samples.
- Question generation for query-agnostic phrase representations: we found that generating questions for every entity in training passages improves the quality of phrase representations where we used a question generation model based on T5. This idea has been further pursued by recent work, which scales up the experiment and shows a large improvement on phrase-indexed QA.
- Query-side fine-tuning: due to a large number of phrase representations, we fix them once they are obtained and further optimize the question encoder. This is shown to be effective for in-domain datasets as well as transfer learning.
Although phrase retrieval was proposed for open-domain QA in the beginning [2], we are now able to use phrase retrieval for different tasks through query-side fine-tuning assuming the set of phrase representations as a latent knowledge base. For instance, we can easily fine-tune our question encoder for slot filling examples where queries are synthesized such as “(Michael Jackson, was a member of, x),” which is a different format of queries compared to the ones from QA datasets, so that the query encoder finds the contextualized phrase representation of “Jackson 5.” In the paper, we show that the accuracy of DensePhrases on slot filling can easily outperform the existing approaches by query-side fine-tuning DensePhrases on few thousand examples.
Phrase Retrieval Learns Passage Retrieval, Too
While we have shown that DensePhrases can be used to retrieve phrase-level knowledge from Wikipedia (or any other corpus of our choice), we were noticing that it also retrieves relevant passages.
Since each phrase is extracted from a passage, we can always locate the phrases and their original passages as shown in Figure 5.
Whenever we retrieve a specific unit of text, which is embdded in a larger context, we can always retrieve a larger units of text (e.g., retrieve phrase ⇒ sentence ⇒ passage), but not vice versa (e.g., retrieve passage ⇏ sentence ⇏ phrase).
Since the definition of phrases used in phrase retrieval—contiguous words up to length L—includes single words, this is the smallest meaningful retrieval unit that we have.
Based on this motivation, our recent paper [5] formulates phrase-based passage retrieval that defines passage retrieval scores based on phrase retrieval scores as follows:
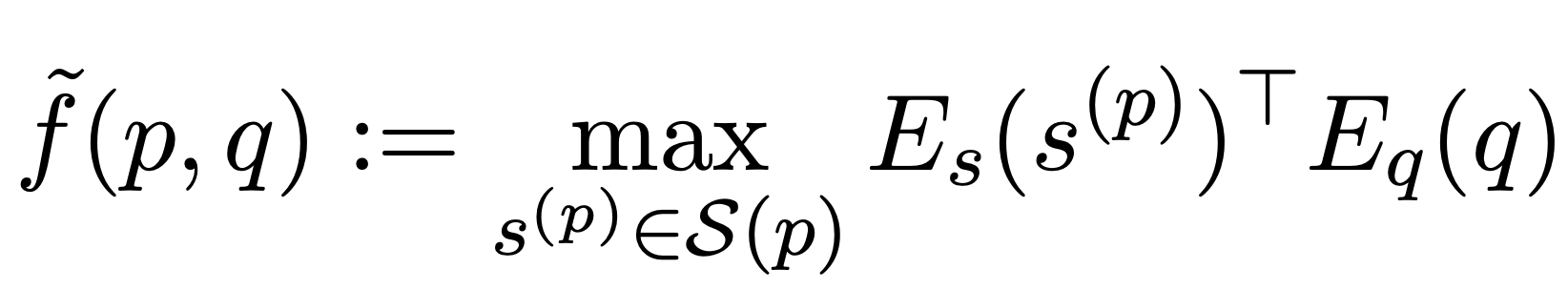
Equation 1. Equation of phrase-based passage retrieval. The score of passage retrieval is defined as the maximum phrase retrieval score within the passage p. S(p) is the set of all the phrases in p.
The formulation can be easily modified depending on the choice of granularity (e.g., sentence).
Interestingly, using the formulation above, DensePhrases without any passage-level training signal can easily outperform Dense Passage Retriever (DPR [9]) in terms of its passage retrieval accuracy (Table 6) and other information retrieval metrics (shown in the paper).
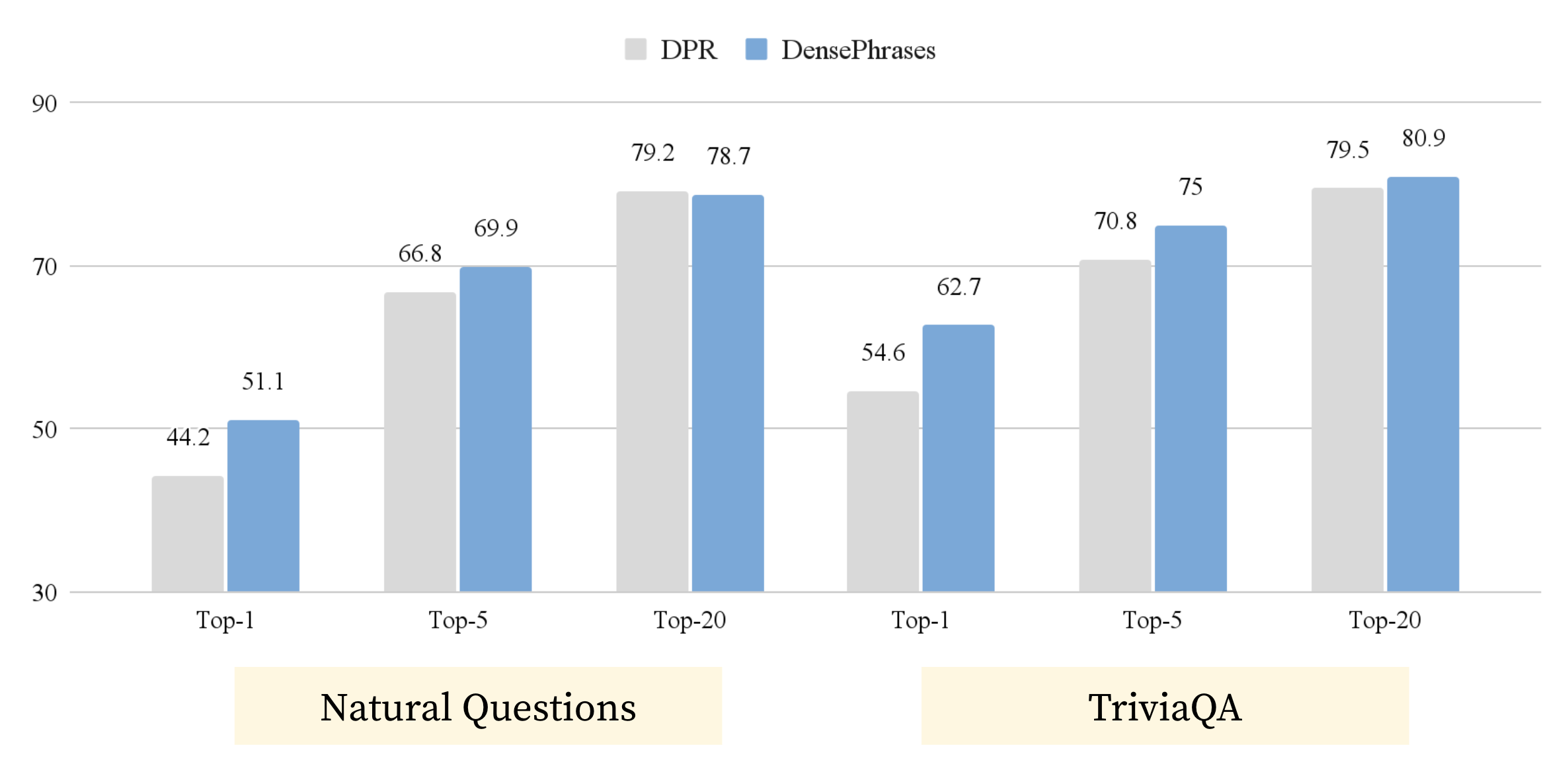
Figure 6. DensePhrases with phrase-based passage retrieval can easily outperform DPR on passage retrieval for open-domain QA. Evaluated on Natural Questions and TriviaQA.
To provide a unified view of text retrieval, we provide our analysis comparing DensePhrases and DPR and show why DensePhrases can naturally learn passage retrieval, too. Since DensePhrases differentiates positive and negative phrases in the same passage (we call this type of negatives as in-passage negatives), it has a very similar role as BM25 hard negatives in DPR, which helps it finding a passage that contains the exact answer.

Figure 7. While DensePhrases and DPR both use in-batch negatives, DensePhrases uses in-passage negatives (contrasting positive and negative phrases in the same passage) which helps it finding correct passages.
Based on our preliminary experiment and analysis, we show that the followings are possible with DensePhrases:
- DensePhrases as a passage retriever for open-domain QA: superior performance of DensePhrases over DPR on passage retrieval also translates to better performance on end-to-end open-domain QA performance with the state-of-the-art architecture [8].
- DensePhrases as a document retriever for entity linking and dialogue: DensePhrases can be easily adapted to retrieve documents with a slight modification to its loss term.
There have been different methodologies for different granularities of text retrieval, but our findings suggest that we can have a single multi-granularity retriever that can do retrieval of different granularities of our choice. Our paper also includes more efforts to reduce the index size of phrase retrieval (from 307GB to 69GB) with Optimized Product Quantization and quantization-aware training. Now, phrase retrieval has a similar index size compared to passage retrieval.
Conclusion
Initially proposed as an efficient open-domain QA model, phrase retrieval has now become a strong and versatile solution to various text retrieval tasks.
Without running heavy Transformer-based models on the top of retrieved passages, we can easily retrieve phrase-level answers as well as sentence, passage, and document-level answers with very fast inference time.
While the challenge over training high-quality phrase representations is by no means over, my time spent on phrase retrieval for the last three years was a great journey to improve this line of work.
Below is the summary of the improvement we made.
All models, resources and code are also publicly available.
| Model | NQ-open Acc. | Stroage (GB) | #Q/sec (CPU) | Application |
|---|---|---|---|---|
| Seo et al., ACL’19 [2] | 8.1* | 1,200 | 2.4 | Open-domain QA |
| Lee et al., ACL’20 [3] | 14.5* (+6.4) | 1,547 (+29%) | 1.7 (0.7x) | Open-domain QA |
| Lee et al., ACL’21 [4] | 40.9 (+32.8) | 320 (-73%) | 13.6 (5.7x) | + Slot filling |
| Lee et al., EMNLP’21 [5] | 41.3 (+33.2) | 74 (-94%) | 16.7 (7.0x) | + Passage/doc. retrieval |
Table 4. Summary of improvement in phrase retrieval. Numbers in parentheses show absolute (Acc.) or relative (%, x) improvement compared to Seo et al., 2019. *: earlier models were only trained on SQuAD, but simply adding the NQ training data gives a marginal improvement in Lee et al., ACL’20.
| Model | Code |
|---|---|
| PIQA [1] | https://github.com/seominjoon/piqa |
| DenSPI [2] | https://github.com/seominjoon/denspi |
| Sparc [3] | https://github.com/jhyuklee/sparc |
| DensePhrases [4] | https://github.com/princeton-nlp/DensePhrases |
| Phrase-based Passage Retrieval [5] | https://github.com/princeton-nlp/DensePhrases |
Table 5. Links to the code of each model
We hope to see more works starting to use phrase retrieval in their work or trying to improve phrase retrieval in the future.
If you have any questions regarding this post or any works introduced above, I’d be happy to answer them or provide my thoughts (jinhyuklee@cs.princeton.edu)!
Thanks to Danqi Chen, Alexander Wettig, Zexuan Zhong, Vishvak Murahari, Jens Tuyls, and Howard Yen for insightful feedback.
References
[1] Phrase-Indexed Question Answering: A New Challenge for Scalable Document Comprehension Minjoon Seo, Tom Kwiatkowski, Ankur P. Parikh, Ali Farhadi, Hannaneh Hajishirzi. EMNLP 2018
[2] Real-Time Open-Domain Question Answering with Dense-Sparse Phrase Index Minjoon Seo*, Jinhyuk Lee*, Tom Kwiatkowski, Ankur P. Parikh, Ali Farhadi, Hannaneh Hajishirzi. ACL 2019
[3] Contextualized Sparse Representations for Real-Time Open-Domain Question Answering Jinhyuk Lee, Minjoon Seo, Hannaneh Hajishirzi, Jaewoo Kang. ACL 2020
[4] Learning Dense Representations of Phrases at Scale Jinhyuk Lee, Mujeen Sung, Jaewoo Kang, Danqi Chen. ACL 2021
[5] Phrase Retrieval Learns Passage Retrieval, Too Jinhyuk Lee, Alexander Wettig and Danqi Chen. EMNLP 2021
[6] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova. NAACL 2019
[7] Reading Wikipedia to Answer Open-Domain Questions Danqi Chen, Adam Fisch, Jason Weston, Antoine Bordes. ACL 2017
[8] Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering Gautier Izacard, Edouard Grave. EACL 2021
[9] Dense Passage Retrieval for Open-Domain Question Answering Vladimir Karpukhin*, Barlas Oğuz*, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, Wen-tau Yih. EMNLP 2020
*: Equal contribution