Language Agents in the Digital World: Opportunities and Risks
| July 24, 2023 | Written by Shunyu Yao and Karthik Narasimhan |
While 2022 was the year that ignited the public awareness of language models like ChatGPT, 2023 has witnessed the rise of language agents. Papers like ReAct and Toolformers, along with frameworks like LangChain and ChatGPT Plugins, have demonstrated that language models can be connected to webpages, software, tools and APIs, augmenting them with computational tools, and custom, up-to-date information sources. This ability to act and affect the world also enables much broader applications beyond traditional language processing — for example, navigating websites to find information, controlling softwares like Excel, or coding interactively with execution feedback.
{kind=link}
A demo of Adept ACT-1, a language agent that can navigate websites and perform autonomous tasks.
Continuing to call these machines “language models” (which are optimized to predict the next token) substantially downplays their capabilities, since they are evolving towards autonomous agents capable of solving general digital tasks using language as the primary medium — in short, “language agents” in the digital world.
While the demonstrations and papers on language agents look exciting, what does this mean for the future of AI and society? This blog post seeks to offer our insights on this matter and spark discussions centered on the opportunities and risks inherent in the development of language agents. For a technical overview of these agents, check the great blog post by Lilian Weng. Additionally, for more papers, blog posts, benchmarks, and other resources on language agents, visit our repo.
Language Agents in the Digital World: A New Prospect for General-Purpose AI
Artificial intelligence has long been driven by the desire to create autonomous agents that can intelligently interact with their environment to achieve specific goals. Reinforcement learning (RL) is a powerful framework that tackles these challenges, with notable successes like AlphaGo and OpenAI Five. However, RL has perennially suffered from a lack of inductive bias and environmental limitations. Injecting human-like visual-motor or physical priors has been challenging, which means RL models are often trained from scratch using millions of interactions. Consequently, learning in physical, real-world environments has been challenging, since robotic interactions are slow and expensive to collect. This in turn explains why major RL successes have occurred in games with fast and cheap simulations, but also with closed and limited domains that prove difficult to transfer to the complexity of real-world intelligent tasks.
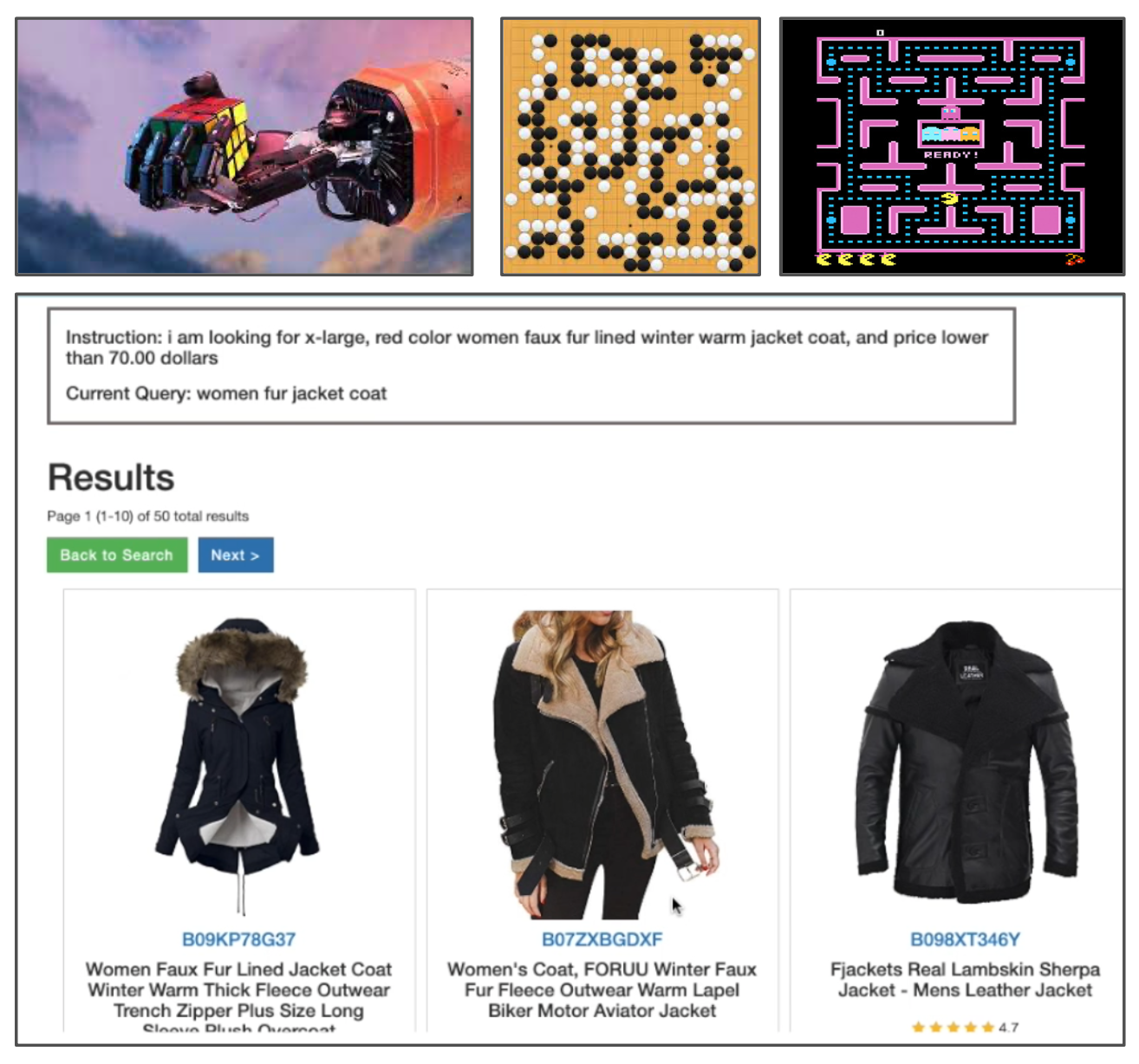
While agents that interact with physical or game environments face challenges in scalable learning or real-world practicality (top), agents that interact with the digital world (bottom) enjoy both benefits.
While physical environments and game worlds each have their shortcomings, the digital world (with language as the main medium) provides uniquely scalable environments and learning advantages. For example, WebShop is a shopping website environment with millions of products, where an agent needs to read webpages, type queries, and click buttons to shop like humans. Such a digital task challenges general aspects of intelligence, including visual understanding, reading comprehension, and decision making, and allows for easy scaling up. It also offers an opportunity to bootstrap agents with pre-trained priors with minimal adaptation — prompting with a large language model can directly work on WebShop or any ChatGPT plugin tasks, which is not easy with traditional RL domains. As more APIs are incorporated into the environment, an ecosystem of extremely diverse and open-ended digital tools and tasks will emerge and foster more general and capable autonomous language agents. This will usher a new direction in the path toward general artificial intelligence.
Massive Potential for an Automated Society
A machine that can act on its own has great promise for alleviating human labor across various domains. From robotic vacuum cleaners to autonomous cars, such machines are often deployed in physical environments with task-specialized algorithms and narrow-ranged applications. Language agents such as ChatGPT plugins and Microsoft 365 Copilot, on the other hand, would present general-purpose solutions to automating a wide range of digital tasks, which is especially timely given that a large percentage of human life and work is taking place digitally.
A glimpse of the forthcoming revolution can be seen in this 95-people study, where Github Copilot reduces the average coding time by more than 50%. However, Github Copilot merely scratches the surface by suggesting actions — a more autonomous agent that iteratively writes, runs, and debugs code leveraging automatic environment feedback (e.g. error information) is on the horizon.
Similar stories can be expected for designers, accountants, lawyers, and any occupations dealing with digital tools and data. Even more boldly, considering the connections between physical and digital worlds through the Internet of Things, language agents can interact with physical environments far beyond Alexa’s simple capabilities such as ‘turning on the lights’. For instance, with cloud robotic laboratory services, language agents can potentially engage in tedious decision making loops for automatic drug discovery: read data, analyze insights, inform next experiment parameters, report potential results, and so much more.
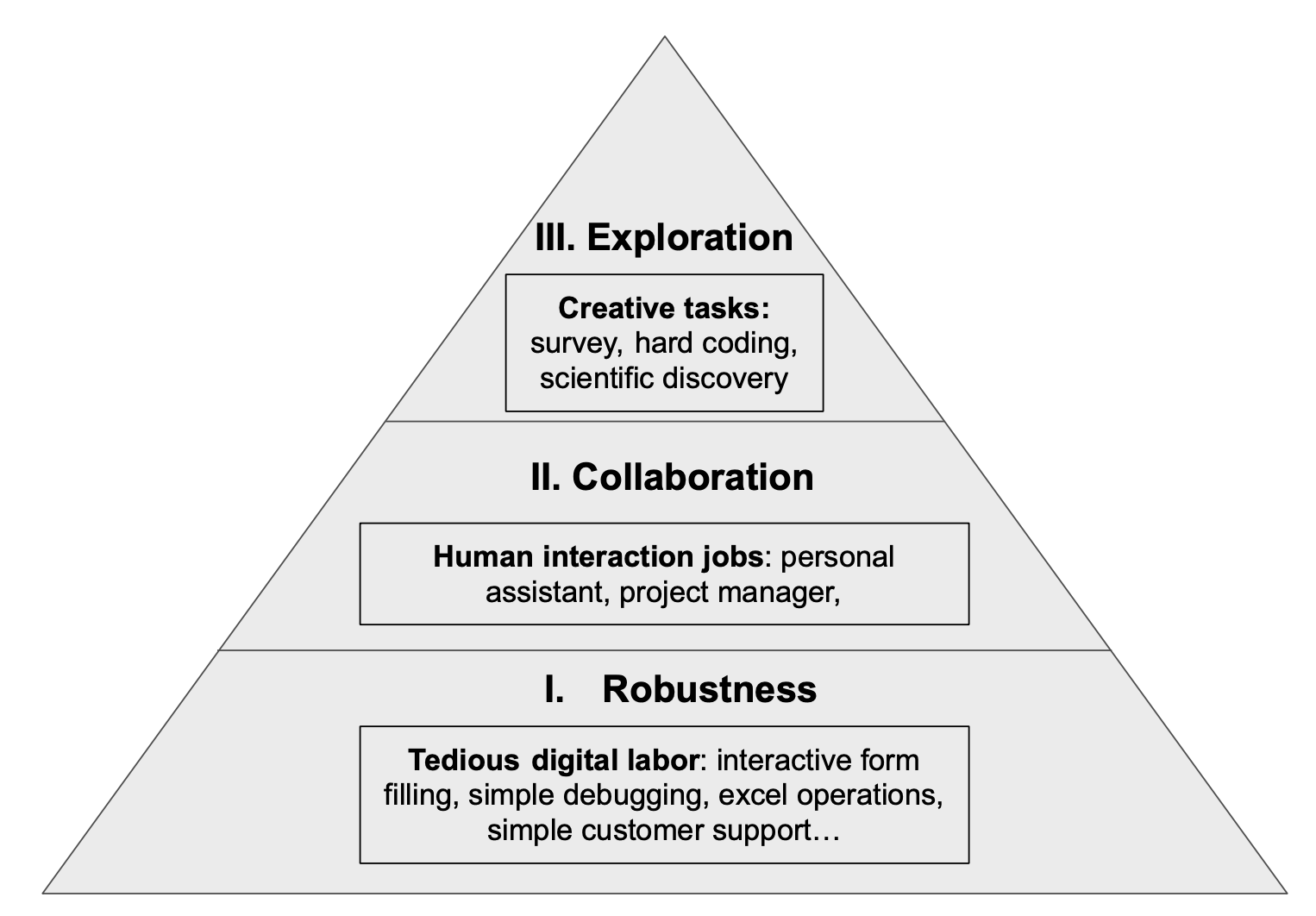
A ladder of job automation opportunities for language agents and the capabilities they may provide.
Given the infinite possibilities, what is a good way to organize them? There seems to be no single answer, just as there are many dimensions to classify or organize human jobs (pay level, work environment, knowledge level, general vs specialist, etc.). Here we want to propose an alternative ladder of three progressive steps based on agent capabilities:
-
Step One: Robustness for tedious digital labor: Tasks like interacting with web pages and software to fill various forms, repetitive excel or customer support operations, or fixing code bugs involve multi-turn information lookup and trial-and-error. Most of these digital activities (perhaps except coding) only require a couple of hours of training to get a human rookie started, yet turn out repetitive and boring for humans, with potential for fatigue-induced errors. Similarly, there seems to be no fundamental barrier to automating these jobs, as providing a couple of examples to GPT-4 can already lead to reasonable performances on many of such simple tasks. However, it is still hard to reach human-level reliability and safety (see sections below). Once they do, a substantial portion of these jobs can be anticipated to undergo automation, possibly heralding the inaugural wave of automation propelled by language agents.
-
Step Two: Collaboration and communication skills for work that requires interaction with digital tools as well as humans: Tasks like making sales while querying and logging information, acting as project managers that log meeting notes and delegate todos, or personal assistants that copilot various digital platforms by noting user preferences fall under this category. These tasks require not only robustness of performing various digital routines, but also human-like communication skills (e.g. pragmatics, theory-of-mind, personality understanding, etc.) in order to ensure successful and long-horizon collaboration with human (or agent) partners. Developing such skills and obtaining human trust are also a gradual process, just like robustifying agents for ever more complex digital work.
-
Step Three: Exploration for creative or knowledge endeavors: This includes drafting reports by accessing literatures and other information online; surveying research fields and proposing research ideas by navigating through the web of knowledge; discovering mathematical knowledge via interaction with logical environments (e.g. Coq). These creative jobs resemble those of scientists, artists, writers, where intrinsic motivation is required to define tasks for oneself and pursue long-horizon, sparse-reward exploration, on top of robust digital and communication skills (e.g. how to search, how to communicate ideas and incorporate feedback, etc.).
Such a ladder also corresponds to different levels of task ambiguity and reward sparsity: from concrete instructions and clear task-completion signals, to contextual, implicit human intentions and pragmatic human feedback inference, and to self-defined tasks with intrinsic reward signals. Researching the latter capabilities does not necessarily need to wait for prior ones, but industrialized deployment probably will follow such an easy-to-hard process.
Balancing Progress and Safety

The issues of robustness, malicious use, job insecurity, and the existential risk. While history teaches us something about the first three, existential risk is less understood and more unknown.
All this progress in automation is also bound to create some fears, ranging from humans losing their jobs to existential risk. We see four kinds of potential issues that need to be addressed with the rise of language agents:
- Robustness in real-world applications: Agents taking actions autonomously create a higher stakes scenario than other applications of LLMs such as text generation or question answering which have issues like bias and toxicity. Since their actions directly affect the world — such as deleting files or executing transactions, and can occur at a large scale with great speed, any small mistakes can have major repercussions and can go undetected before causing great harm.
- Malicious use: Language agents that can accomplish complex tasks also means there is greater potential for malicious use, such as attacking websites, complex phishing schemes or even releasing nuclear weapons — any type of evil hacking possible using a computer. This will require a complete revamp of current defenses, which are mainly deterministic and rely on simple tests like Captchas. Hackers could also inject malicious code into websites or other applications causing benign agents operating over them to misbehave in unintended ways, e.g. revealing sensitive information like social security or credit card numbers.
- Replacing human jobs: As with previous technological advancements, the emergence of language agents will inevitably lead to the displacement of certain job roles while creating new employment opportunities, much like how the advent of cars transformed coachmen into drivers. Certain categories of human jobs in the present day will likely cease to exist and will instead evolve into more abstract jobs where a human oversees a team of agents to accomplish the same tasks with greater efficiency.
- AGI and existential risk: At the extreme level, autonomous agents also represent a big step towards AGI systems that are capable of performing complex tasks at human levels of intelligence across a broad variety of domains. This could result in an existential risk for the human race, especially if agents are provided with the controls to affect change in the world.
How do we address these risks?

Addressing the safety of language agents (and AI in general) requires collaborative and multi-layered efforts from developers, researchers, educators, policymakers, and even AI systems, etc.
The concerns above are actively debated and hardly settled, but we may evaluate them jointly with a historical perspective and critical thinking.
-
Improving robustness via guardrails & calibration: Enhancing the robustness of language agents is a critical aspect that requires the implementation of effective guardrails and calibration mechanisms. Currently, basic measures such as sandboxing or heuristic limitations on the agents’ action space (e.g. OpenAI limited ChatGPT plugins to GET requests on the web or banned os function in Python for CodeX) are employed to prevent unsafe behavior or error propagation. However, as language agents become increasingly autonomous and operate in more complex action spaces, ensuring their safety becomes more challenging. To address this, several potential avenues can be explored:
-
Human in the loop for trust: Adopting a gradual and cautious deployment approach that incorporates human oversight and alignment-oriented processes. This involves having human reviewers or supervisors involved in monitoring and guiding the behavior of language agents during their deployment. By incorporating human judgment and expertise, potential risks and unintended consequences can be identified and mitigated in a timely manner. This approach aligns with the research on human-in-the-loop systems.
-
Formal guarantees for worst-case results: Exploring the development of formal guarantees that ensure the language agents’ behavior remains within acceptable bounds in a given action space. Drawing inspiration from adversarial reinforcement learning (RL) research, where techniques are developed to defend RL agents against adversarial attacks, similar approaches can be adapted to provide formal assurances of safety and robustness for language agents. By establishing boundaries and constraints on the agents’ actions, worst-case scenarios can be mitigated.
-
Prompt-based behavior guidelines like Constitutional AI: Employing prompt-based behavior guidelines inspired by legal frameworks such as constitutional law. By training language agents to follow specific prompt instructions that adhere to ethical principles and guidelines, the behavior of the agents can be guided and aligned with desired societal norms. This approach involves defining clear and explicit rules for language agents to ensure responsible and ethical behavior.
-
-
Preventing malicious use through regulation: Ensuring the responsible ownership, control, and oversight of large language models and their usage is crucial. On top of the following technical solutions to robustness and safeguarding, it also involves the implementation of laws, regulations, and policies to govern their deployment. One example is OpenAI’s proposal for a licensing system for really big models, an idea that might soon be implemented in countries like China. Additionally, strict data permission protocols and regulations can be established to safeguard against misuse and unauthorized access to sensitive information. It is also important to consider the potential for criminal activities and establish punitive measures accordingly, drawing lessons from the realm of cryptocurrency crimes and their legal consequences.
3) Impact on jobs and the need for education and policy: To address the (likely) job crisis, it is crucial to implement comprehensive education and policy initiatives. By equipping individuals with the necessary skills and knowledge to adapt to the changing landscape, we can facilitate the smooth integration of language agents into various industries. This can be achieved through educational programs, vocational training, and re-skilling initiatives that prepare the workforce for the demands of a technology-driven future.
4) Managing existential risks through understanding and research: Before taking any further action, it is imperative that we deepen our understanding of language agents and their implications. This involves gaining a mechanistic understanding of how these models operate, their limitations, and their potential risks. Furthermore, it is crucial to establish scalable oversight mechanisms to ensure responsible deployment and prevent potential misuse. One approach is to utilize language agents themselves to monitor and assess the behavior of other language agents, enabling proactive identification and mitigation of any harmful consequences. Promoting further research in the field of language agents will contribute to a more comprehensive understanding of their safety implications and assist in the development of effective safeguards for society.
Final Thoughts
If deployed responsibly, language agents hold great promise for general artificial intelligence and automating a significant portion of existing human labor, perhaps starting a new era of scalable human-AI collaboration. However, there remain several risks that must be considered immediately and mitigated effectively to avoid undesirable consequences, as is true with any new technology. We believe this blog post only serves as a starting point, and look forward to community discussions and working together to make safe advances in language agents.
Citation
Yao, Shunyu and Narasimhan, Karthik (Jul 2023). “Language Agents in the Digital World: Opportunities and Risks”. Princeton NLP Blog. https://princeton-nlp.github.io/language-agent-impact/.
@article{yao2023impact,
title = "Language Agents in the Digital World: Opportunities and Risks",
author = "Yao, Shunyu and Narasimhan, Karthik",
journal = "princeton-nlp.github.io",
year = "2023",
month = "Jul",
url = "https://princeton-nlp.github.io/language-agent-impact/"
}
Acknowledgement
Thank Yuqian Sun for the help with figures!
The subject is very new and we welcome any feedback! Feel free to comment below this tweet on anything about the blog post.