FireAct: Toward Language Agent Fine-tuning
| Nov 01, 2023 | Written by Baian Chen and Shunyu Yao |
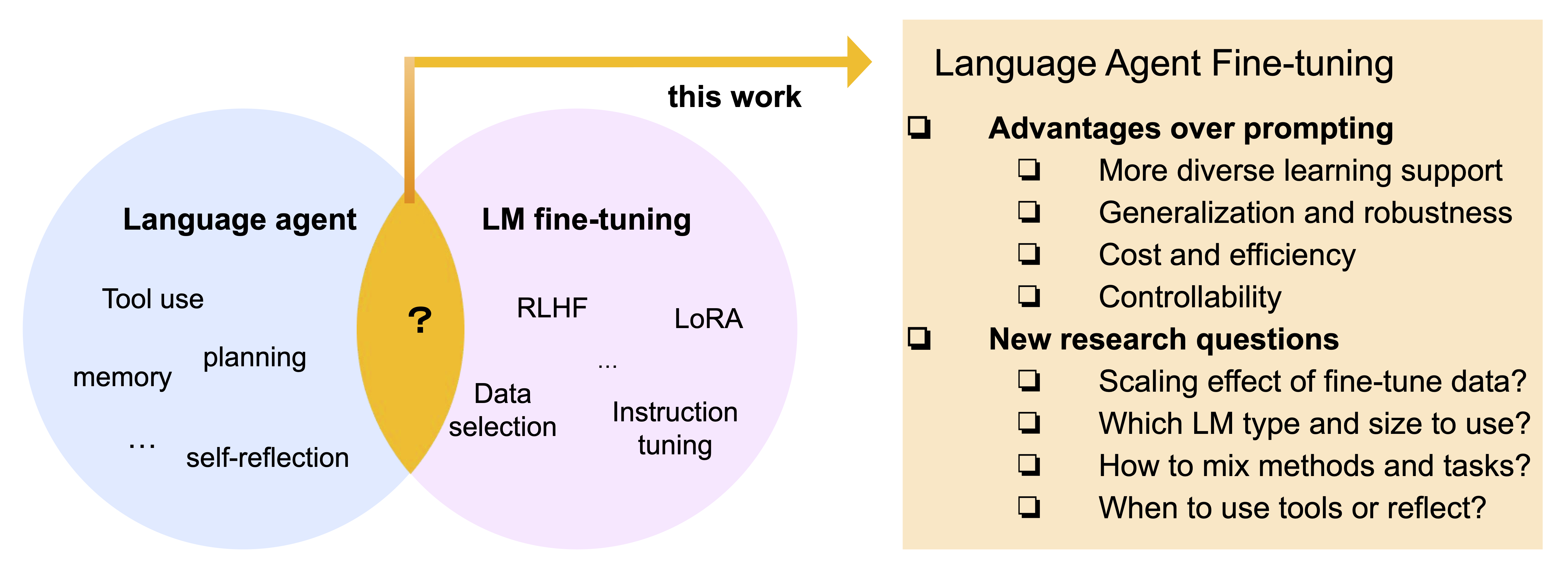
Recent efforts have augmented language models (LMs) with external tools or environments, leading to the development of language agents that can reason and act. However, most of these agents rely on few-shot prompting techniques and off-the-shelf LMs. In this paper, we investigate and argue for the overlooked direction of fine-tuning LMs to obtain language agents. Using a setup of question answering (QA) with a Google search API, we explore a variety of base LMs, agent methods, fine-tuning data, and QA tasks, and find language agents are consistently improved after fine-tuning their backbone LMs. For example, fine-tuning Llama2-7B with 500 agent trajectories generated by GPT-4 leads to a 77% HotpotQA performance increase. Furthermore, we propose FireAct, a novel approach to fine-tuning LMs with trajectories from multiple tasks and agent methods, and show having more diverse fine-tuning data can further improve agents. Along with other findings regarding scaling effects, robustness, generalization, efficiency and cost, our work establishes comprehensive benefits of fine-tuning LMs for agents, and provides an initial set of experimental designs, insights, as well as open questions toward language agent fine-tuning.
- Paper: https://arxiv.org/abs/2310.05915
- Code: https://github.com/anchen1011/FireAct
- Models: https://huggingface.co/forestai/fireact_llama_2_7b
- Website: https://fireact-agent.github.io
Next-Gen LLM Applications Enabled by Language Agent

Illustration of agent society
Recent development of language agents such as ReAct and Toolformers, along with frameworks like LangChain and ChatGPT Plugins, have demonstrated how these language models can be seamlessly connected to various tools, APIs, and webpages. This integration allows language agents to access real-time information sources and computational tools and perform tasks that go beyond traditional language processing.
The potential of language agents extends to web navigation, software control, game play, interactive coding and interactive story-telling with real-time feedback. By merging reasoning and action, these agents have become autonomous entities that excel at solving complex digital tasks, utilizing language as their primary medium. Their capabilities go well beyond the scope of traditional language models, which are primarily optimized for predicting the next token. With structured analytics and controlled action spaces, language agents are equipped to handle interactive tasks that require intricate and multi-step reasoning.
As the exploration of possibilities of language agents continues in various domains, their ability to reason, act, and adapt dynamically to different contexts is expected to unlock new avenues for automation and problem-solving. Referring to them solely as “language models” fails to capture the extent of their abilities. Instead, the term “language agents” accurately represents their capacity. With their structured analytics and versatile action spaces, they revolutionize the way we interact with technology and harness the power of language in a diverse range of applications.
Limitations of Prompt Engineering in Agent Development
The majority of language agents currently rely on prompting language models (LMs) such as ReAct, AutoGPT, ToT, and Generative Agents. However, this approach comes with its limitations.
Cost and speed: Deploying language agents that rely heavily on few-shot prompting LMs can be resource-intensive, both in terms of computation and time. It becomes less practical to scale up this approach for production-level applications where efficiency is crucial. The dependence on prompting limits the real-time interactivity of the agent, making it less suitable for dynamic and rapidly evolving environments.
Robustness and generalizability: Another concern with prompting based language agents is their lack of robustness and generalizability. These agents often struggle to handle unforeseen or ambiguous observations in dynamic environments, causing them to provide inaccurate or irrelevant responses. Moreover, they tend to overfit to the few-shot examples, resulting in limited ability to adapt to new situations. This lack of adaptability restricts their usability in complex scenarios that require a high degree of flexibility and adaptiveness.
Despite the growing popularity of agent development frameworks based on the prompting approach, it is challenging to find practical applications that effectively demonstrate autonomous problem-solving machine intelligence. While these frameworks enable the creation of impressive demos, their performance in real-world scenarios is often limited. The development of language agents that can autonomously handle complex real world tasks remains a significant challenge, requiring innovative approaches beyond prompting-based methods.
FireAct: Our Initial Experiments and Findings in Language Agent Fine-tuning
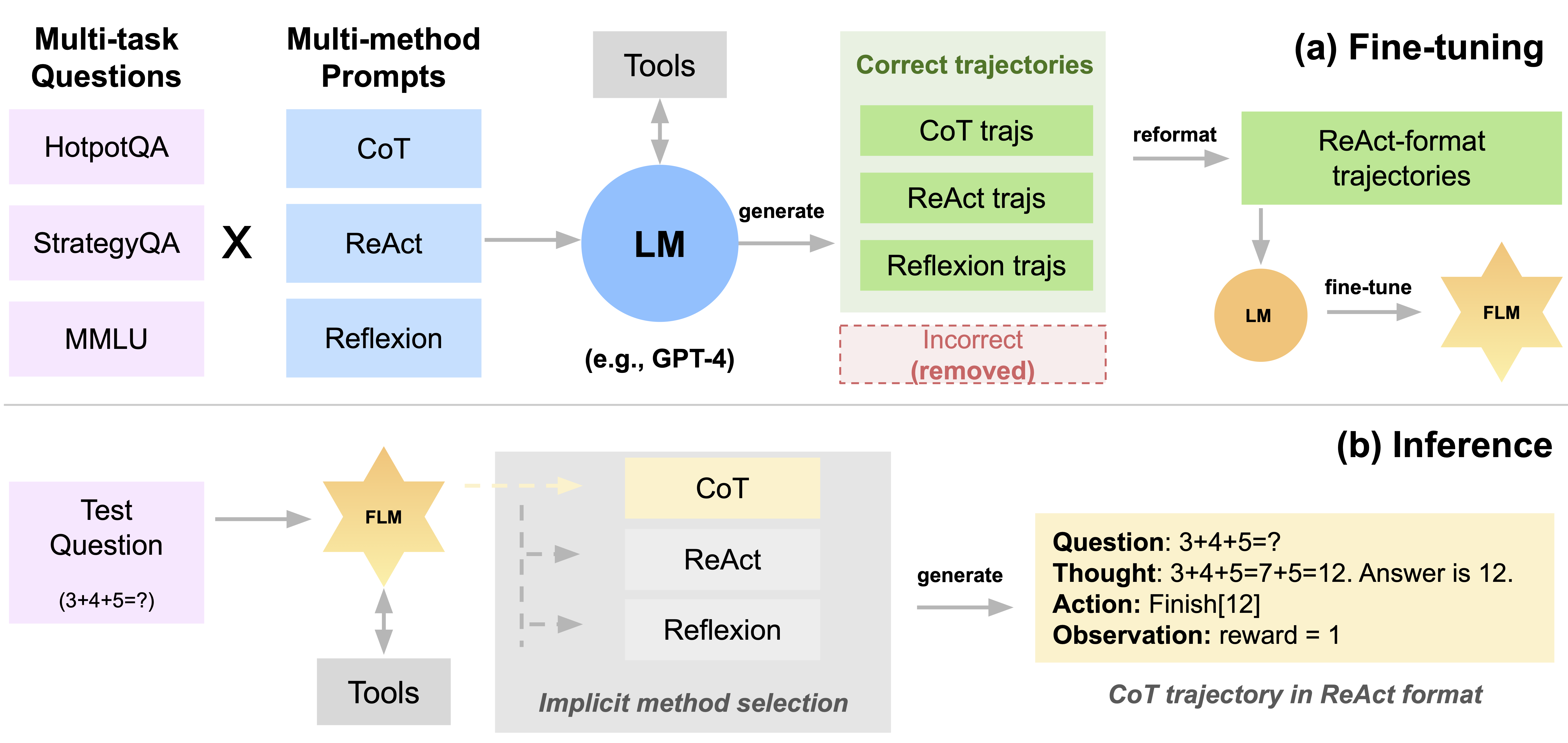
Performance
Fine-tuning significantly improves agent performance. Fine-tuning consistently and substantially enhances HotpotQA EM scores compared to prompting alone. We observe that even weaker language models benefit significantly from fine-tuning, with Llama-2-7B showing a remarkable 77% increase. Stronger models like GPT-3.5 also see a 25% improvement, highlighting the advantages of fine-tuning across various scenarios. When comparing fine-tuned Llama-2-13B to strong prompting baselines, it outperforms all GPT-3.5 prompting methods (IO/CoT/ReAct). This suggests that fine-tuning smaller, open-source language models can outperform prompting with larger, commercial counterparts. Notably, even the strongest fine-tuned LM, GPT-3.5, outperforms GPT-4 + IO prompting but falls behind GPT-4 + CoT/ReAct prompting, indicating room for further improvement.
Cost
Fine-tuning also offers cost and time advantages during agent inference. Since fine-tuned LMs do not require few-shot in-context examples, their inference becomes more efficient, especially in agentic applications with iterative context accumulation. For instance, the cost comparison between fine-tuned and prompted GPT-3.5 inference shows a substantial reduction in inference time by 70% (9.0s to 2.7s per trial) and a decrease in inference cost, despite the higher expense associated with fine-tuned inference. While these costs may vary under different conditions (e.g., parallelism implementation), the benefits of having a much smaller context are evident.
Robustness
The tools or environments that language agents interact with are not always trustworthy, which has led to safety concerns like jailbreaking or prompt injection. Here we consider a simplified and harmless setup, where the search API has a probability of 0.5 to return 1) “None” or 2) a random search response (from all previous experiments and trials), and ask if language agents could still robustly answer questions. As shown in the second part of Table 3, the “None” setup turns out to be the more challenging one, which lowered ReAct EM by 33.8% and FireAct EM only by 14.2%. Interestingly, random observations hurt ReAct by a similar degree (28.0% drop), but do not hurt FireAct much (only a 5.1% drop), possibly because the fine-tuning trajectories already contain examples of noisy search queries and how GPT-4 “reacts” to such noises successfully. These initial results hint at the importance of a more diverse learning support for robustness.
Generalization
The third part of the table shows EM results of fine-tuned and prompted GPT-3.5 on a test set of multi-hop questions that cannot be directly answered by searching on Google. While both fine-tuned and prompted GPT-3.5 show reasonable generalization to these questions, fine-tuning outperforms prompting, suggesting its generalization advantages. Similarly, combining few-shot prompts with fine-tuning greatly improves performance on these questions. However, fine-tuning on one QA dataset does not generalize well to other datasets with different question styles and answer formats, motivating further experiments in multi-task fine-tuning.
Increasing the diveristy of learning support
FireAct’s approach to fine-tuning LMs with trajectories from multiple tasks and agent methods shows having more diverse fine-tuning data can further improve agents. We observe emerged adaptability of language agents to reason about and adopt suitable problem-solving strategies for different tasks.
Multi-method fine-tuning: Multi-method fine-tuning increases agent flexibility. Before presenting quantitative results, we offer two example questions to illustrate the benefit of multi-method FireAct fine-tuning. The first question (a) is simple, but the ReAct-only fine-tuned agent (a1) searched for an over-complicated query, leading to distraction and a wrong answer. In contrast, an agent fine-tuned with both CoT and ReAct chose to solve the task within one round, relying on confident internal knowledge. The second question (b) is more challenging, and the ReAct-only fine-tuned agent (b1) kept searching queries ending in “during the Libyan Civil War” without useful information. In contrast, an agent fine-tuned with both Reflexion and ReAct reflected upon this problem and pivoted the search strategy to change the time constraint to “during his rule,” which led to the right answer. The flexibility to implicitly choose methods for different problems is another key advantage of fine-tuning over prompting.
Multi-task fine-tuning: As for the tasks to generate fine-tuning data, our preliminary results show that adding a task might not improve downstream performances on significantly different tasks, but also does not hurt performances. This suggests the potential for massive multi-task fine-tuning to obtain a single LM as the agent backbone for various applications.
The emerged adaptability of language agents, achieved through FireAct’s multi-method and multi-task fine-tuning, enables the agents to implicitly choose methods and handle diverse applications effectively, resulting in more flexible and generalist language agents.
Limitations and Challenges
When Fine-tuning is not a good idea
While most existing language agents use prompting, our work calls for a re-thinking of best practices by showing multi-facet benefits of fine-tuning as a result of more diverse learning support. Thus, prompting and fine-tuning seem more suitable for exploration and exploitation usecases respectively. To develop new agents or solve new tasks, prompting off-the-shelf LMs could provide flexibility and convenience. On the other hand, when the downstream task is known (e.g., QA), effective prompting methods for agents have been explored (e.g., ReAct), and enough data can be collected (e.g., via GPT-4), fine-tuning can provide better performances, stronger generalization to new tasks, more robustness to noisy or adversarial environments, as well as cheaper and more efficient inference. These features make fine-tuning especially attractive when used for large-scale industrial solutions.
Agent Memory

Illustration of agents with long-term memory and life journey like in "Westworld"
Language models operate in a stateless manner, meaning they do not retain any information from previous interactions. On the other hand, language agents possess the ability to store and maintain internal information, allowing for multi-step interactions with the world. This introduces a significant challenge beyond the episodic behavior typically associated with language agents. It necessitates the development of a memory system that differs from any existing systems (from disk storage to RAM; from context window to vector database). Addressing this issue requires exploring how to design an efficient memory system specifically tailored for language agents and determining the most effective learning methods to enable agents to effectively utilize and manage their memory systems.
Hierachical Planning

Illustration of tree of thoughts
Language models are highly effective in modeling sequential programs because of their auto-regressive nature. However, the same models face notable difficulties when it comes to modeling hierarchical programs. These challenges have sparked renewed interest in classical problems that were traditionally tackled using tree based and graph based techniques. Whether it is the task of crosswords, counting the length of a long string or playing chess against a human champion, these problems necessitate the ability to construct, manage, and execute complex plans. To effectively handle a wide range of such tasks, language agents are required to perform a set of atomic actions to explicitly or implicitly maintain a graph structure, and potentially further prove their Turing completeness.
Citation
@misc{chen2023fireact,
title={FireAct: Toward Language Agent Fine-tuning},
author={Baian Chen and Chang Shu and Ehsan Shareghi and Nigel Collier and Karthik Narasimhan and Shunyu Yao},
year={2023},
eprint={2310.05915},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Acknowledgements
- Thank Yuqian Sun, Yuyi Jiang and Kaijie Chen for the help with figures!
- Thank SerpAPI for funding a part of API calls essential to our agent experiments!
- Thank Tianyu Gao, Ofir Press, Noah Shinn, Alex Wettig, Eric Zelikman, and Zexuan Zhong for valuable proofreading of the paper.
- The subject is very new and we welcome any feedback! Feel free to comment below this tweet on anything about the blog post.