Computing olympiads contain some of the most challenging problems for humans, requiring complex algorithmic reasoning, puzzle solving, in addition to generating efficient code. However, it has been understudied as a domain to evaluate language models (LMs).
In this paper, we introduce the USACO benchmark with 307 problems from the USA Computing Olympiad, along with high-quality unit tests, reference code, and official analyses for each problem. These resources enable us to construct and test a range of LM inference methods for competitive programming for the first time. We find GPT-4 only achieves a 8.7% pass@1 accuracy with zero-shot chain-of-thought prompting, and our best inference method improves it to 20.2% using a combination of self-reflection and retrieval over episodic knowledge.
However, this is far from solving the benchmark. To better understand the remaining challenges, we design a novel human-in-the-loop study and surprisingly find that a small number of targeted hints enable GPT-4 to solve 13 out of 15 problems previously unsolvable by any model and method. Our benchmark, baseline methods, quantitative results, and qualitative analysis serve as an initial step toward LMs with grounded, creative, and algorithmic reasoning.
Baseline's Code Submission
Code loading...Execution result loading...
Note 1: For Episodic Retrieval, GPT-3.5 performed best given top 1 retrieved problem; GPT-4 performed best given top 2. (as shown)
Note 2: Unsolved problem lists are based on 10 zero-shot attempts and 1 Reflexion + Episodic Retrieval attempt per problem; aggregate statistics may differ slightly from paper due to nondeterminism.
Note 3: Some Official Solution Code entries underwent LLM-assisted translation into Python (e.g. from C++); they are verified to pass system tests under given time and memory constraints.

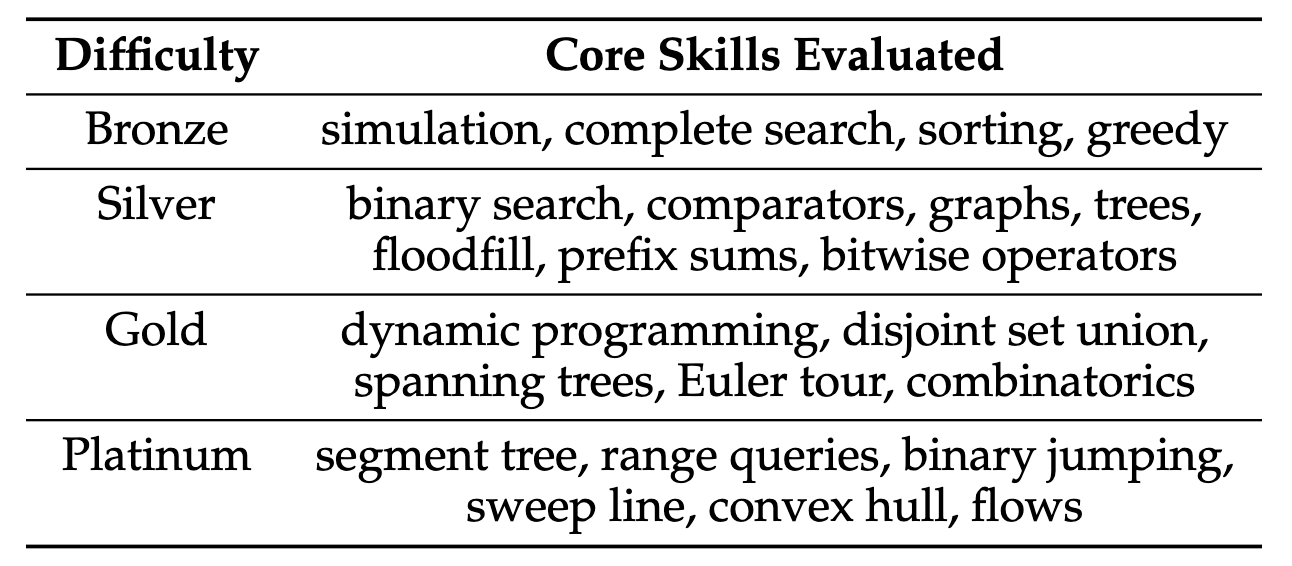
USACO's 307 problems span four difficulty tiers (bronze, silver, gold, platinum). At all levels, solutions typically require ad hoc algorithmic reasoning and, unlike interview-level problems, rarely follow directly from well-known algorithms. Silver and above problems may additionally require knowledge of known algorithms and data structures, often using them in unorthodox ways. The table of per-difficulty core skills summarizes information at usaco.guide.
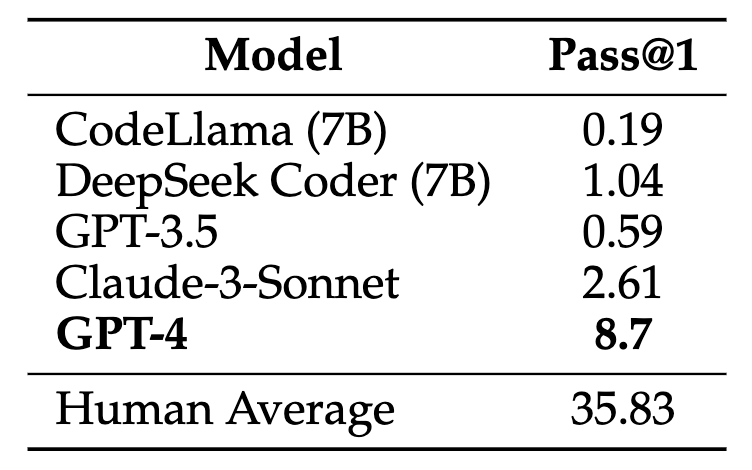
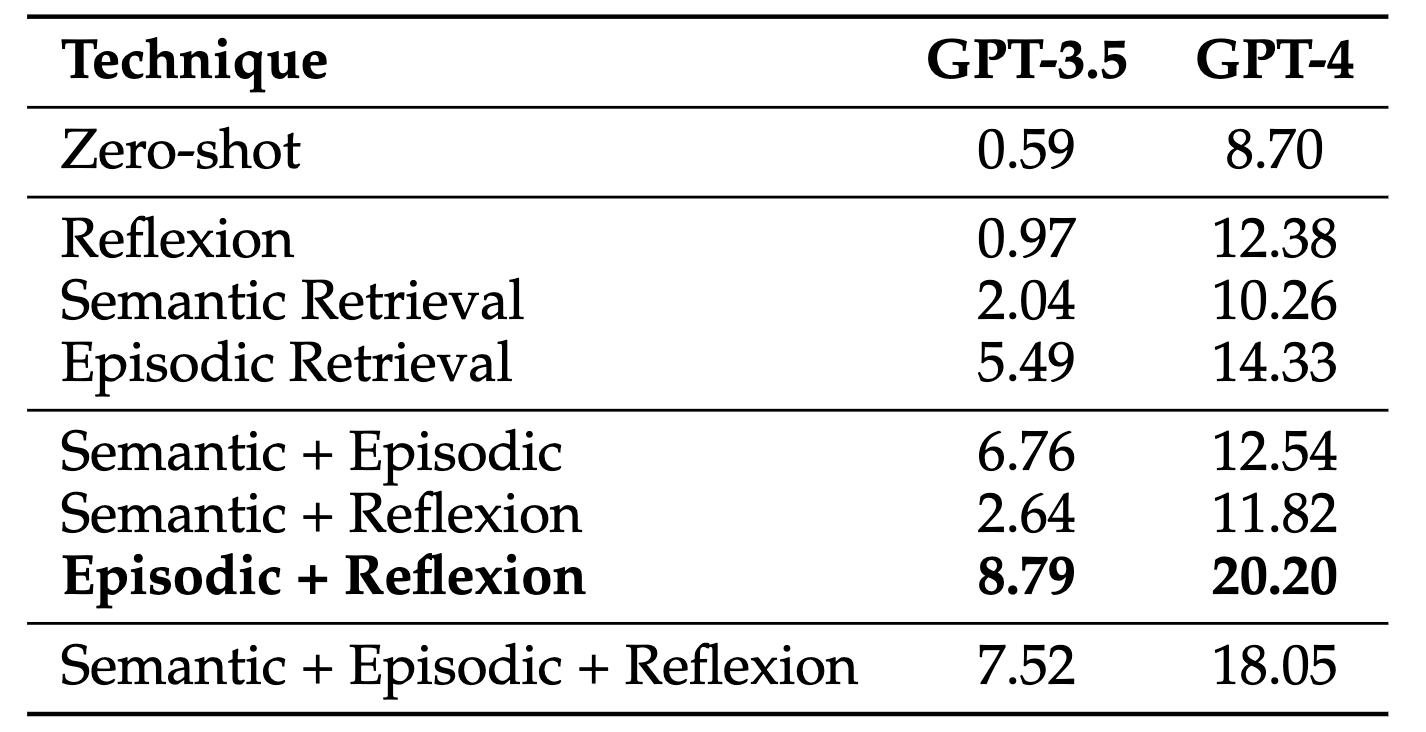
Past work has demonstrated that curated prompting and retrieval strategies can significantly improve performance on various tasks across natural language processing, multi-task QA, and embodied intelligence. We investigate the effectiveness of these methods on the challenging USACO task, and find that:
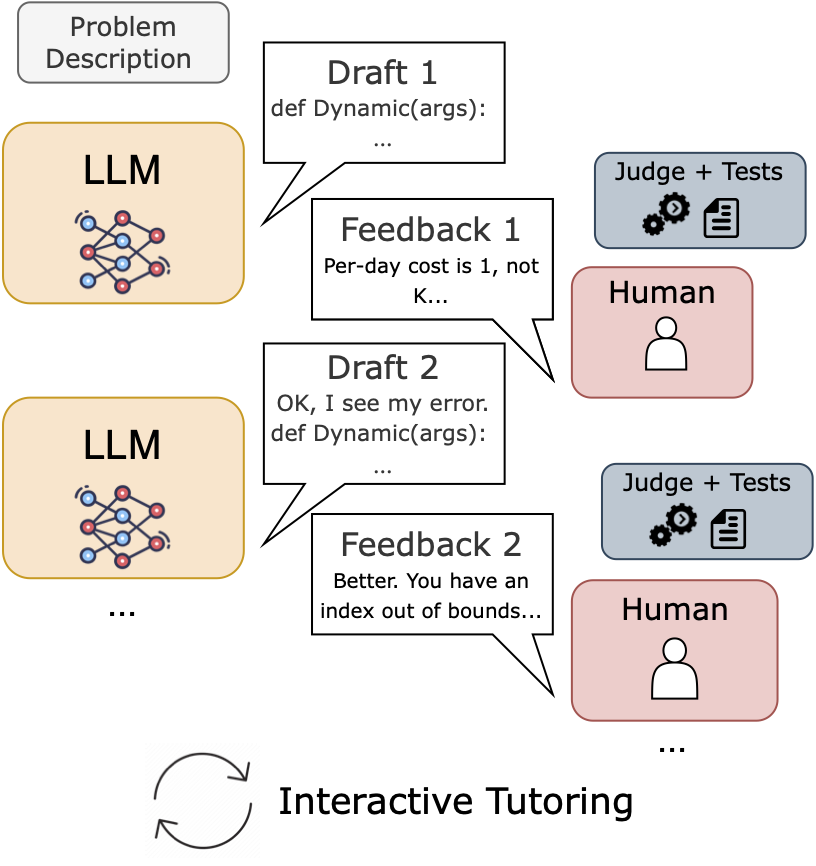

To further examine how far a model is from solving a given problem, we perform a human study via an interactive tutoring setup, in which a human provided with problem solutions engages in a multi-turn conversation with the model providing precise feedback on model errors while following a ruleset that prohibits giving away too much information.
Overall, our human-in-the-loop results highlight that the full capabilities of models may not be captured by solve rate, motivating better evaluation beyond execution success (pass@k) as well as better methods to surface high-quality feedback and leverage this latent ability to adapt in models like GPT-4.
@misc{shi2024language,
title={Can Language Models Solve Olympiad Programming?},
author={Quan Shi and Michael Tang and Karthik Narasimhan and Shunyu Yao},
year={2024},
eprint={2404.10952},
archivePrefix={arXiv},
primaryClass={cs.CL}
}